Armazenamento no Docker
Olá, e obrigado por sua visita! Já faz um bom tempo que escrevi o segundo capítulo da nossa série, e estava mais do que na hora de dar continuidade. Vamos seguir adiante. Neste capítulo, vamos entender como funciona o gerenciamento de armazenamento em containers Docker.
Você aprendeu que Docker, além de ser o nome da empresa criadora da solução, é o nome geral de vários componentes que fazem parte do produto. Temos o principal (Engine), o alternativo para sistemas operacionais que não suportam o principal diretamente (Machine), o criador de ambientes (Compose), e o repositório de imagens (Registry). Vejamos como a solução gerencia disco e arquivos.
Se quiser conferir os outros capítulos:
*** Como este post é um pouco extenso, você pode ter uma melhor experiência de leitura a partir do computador. ***
Alguns fundamentos
Primeiro, precisamos reforçar alguns conceitos fundamentais do mundo de containers, e claro, do Docker:
- Containers são isolados um do outro por natureza, o que significa que eles não podem se comunicar, a menos que explicitamente permitido;
- Containers são criados para serem efêmeros. Você talvez ainda veja bastante este termo em literatura relacionada. Significa que ele deve existir apenas enquanto seja necessário. Em outras palavras, containers são descartáveis/transientes;
- Sem que seja indicado um local para armazenamento permanente de arquivos, o container só consegue enxergar seu próprio sistema de arquivos, mapeado em RAM pelo Docker Engine, ou outro produto equivalente. Quando são encerrados (estado “exited” ou “stopped”), tais alterações são gravadas em disco, e ficam lá até que os containers sejam removidos.
Tenha isto sempre em mente, pois são conceitos válidos para qualquer implementação de containers.
Enquanto um container está no ar, um único ponto de montagem, por default é apresentado a ele: o /. Assim, todos os arquivos que você ou uma aplicação criem ou alterem são armazenados lá. Enquanto o container estiver em execução, ou mesmo parado, mas ainda existente no seu sistema, os arquivos permanecerão nesse sistema de arquivos /. Tenha em mente que um container pode ser instanciado a partir de uma imagem que monta o sistema de arquivos como leitura, o que exigiria um ponto de montagem externo para permitir gravação.
Storage Backend: o AUFS
A parte mais importante do Docker quando lidando com armazenamento é o backend, ou storage driver. É o mecanismo responsável por criar uma visão única de sistema de arquivos para o container. Alguns exemplos são: AUFS, overlay, overlay2, devicemapper, zfs e vfs. No caso do Docker, um dos storage backends mais famosos e usados, principalmente em distribuições Linux, é o AUFS.
Quando executando o Docker em sistemas não-Linux, cada backend suporta determinados tipos de sistemas de arquivo (backing filesystems). A documentação oficial aponta quais backends são recomendados para cada distribuição Linux.
O AUFS, ou Advanced Multi-layered Unification Filesystem usa o conceito de union mount points, segundo o qual diversas camadas são agrupadas em uma única camada, dando à impressão para o container de que existe apenas um sistema de arquivos disponível. Estas camadas são partes componentes da imagem que dá origem ao container. Todas as camadas são montadas como somente leitura, com exceção da última, que é usada pelo container para gravar seus dados. O objetivo de montar as camadas como leitura é para evitar que o container possa realizar alterações em camadas anteriores àquela em que ele se encontra em execução, o que poderia significar alteração da imagem inicial da qual ele foi baseado.
No capítulo anterior, você viu que existe um arquivo especial usado para instruir como um container pode ser criado. Trata-se do Dockerfile. Todo Dockerfile precisa fazer referência a uma imagem, como Ubuntu, Debian, ou CentOS. A partir dela, são feitas operações desejadas no container, como atualização do sistema, instalação de determinado software, cópia de arquivos e execução de programas. Vejamos um exemplo de Dockerfile:
FROM debian:wheezy RUN apt-get install apache2 RUN apt-get install default-jre RUN apt-get install tomcat COPY aplicacao.war /var/lib/tomcat7/webapps
Quando interpretado pelo Docker Engine, através da instrução “build” para construir um container (veremos isso em um futuro capítulo), este arquivo informa exatamente o seguinte:
- Usar como base a imagem Debian com o tag “wheezy”. Cada imagem pode ou não possuir um tag. Para poder usar uma mesma categoria de imagens, mas com conteúdos diferentes, usa-se o artifício de tag. Isto também vale para imagens armazenadas localmente em seu computador;
- Executar o comando “apt-get install” para instalar o Apache2 (servidor web);
- Executar o comando “apt-get install” para instalar o JRE (Java Runtime Environment);
- Executar o comando “apt-get install” para instalar o Tomcat (servidor de aplicações);
- Copiar o arquivo “aplicacao.war” para dentro do diretório “/var/lib/tomcat7/webapps”.
Cada instrução anterior corresponde a uma camada que será adicionada ao sistema de arquivos virtual do container. Assim, a estrutura final disponível para um container construído a partir deste Dockerfile seria aquela apresentada na Figura 1.

Figura 1: camadas do sistema de arquivos – crédito: Spantree
A camada inferior (Linux Kernel 3.13.3) não está no container, e corresponde ao sistema de arquivos do próprio host. A partir daí, todas as outras (em azul ou verde) estão montadas (empilhadas) num formato somente leitura. A última, no topo em vermelho, corresponde à camada de runtime e está liberada para gravação pelo container.
Esta forma de agrupamento permite um reuso junto aos containers. Ou seja, a partir de uma determinada imagem construída por meio de um Dockerfile, posso iniciar diversos containers, e eles todos farão referência ao mesmo esquema de camadas, sendo impossibilitados de gravar qualquer coisa nas camadas inferiores, devidamente protegidas sob o modo “apenas leitura”. Isso também, obviamente, reduz a quantidade de espaço em disco necessário, pois todos os containers compartilham a mesma imagem de base.
Juntamente com o esquema de camadas, o storage backend faz uso do conceito de CoW (Copy on Write) quando o container precisa modificar alguma coisa que se localiza numa das camadas que está protegida contra gravação. Neste momento, a tecnologia funciona da seguinte maneira: ela cria uma cópia do dado a ser modificado e apresenta esta cópia ao container. Ele, por sua vez, altera e efetua a gravação. Na verdade, trata-se de um conceito usado em programação concorrente.
Uma desvantagem grande de permitir ao container gravar em seu sistema de arquivos originalmente apresentado por meio do storage driver é que ele é fortemente acoplado ao host onde está sendo executado. Normalmente, o Docker armazena alterações no diretório /var/lib/docker, mas isso pode mudar dependendo da versão e do sistema operacional onde foi instalado. Assim, não é recomendável usar tal forma de armazenamento. Outra desvantagem é que, uma vez que o container seja removido, quaisquer alterações feitas por ele são perdidas definitivamente.
Por fim, o storage driver implica em perda de desempenho, por precisar traduzir as instruções entre o sistema de arquivos real do host e aquele apresentado ao container para seu uso. Há alternativas melhores para atingir o mesmo objetivo.
Alternativas: Volumes, Pontos de Montagem e tmpfs
O uso de storage backend apresenta as desvantagens explicadas no tópico anterior. Para escapar delas, existem outros mecanismos, mais eficientes, que podem (e devem) ser usados em sua implementação de containers. São eles: volumes, pontos de montagem (ou mount points) e o tmpfs (sistema de arquivos em memória). A Figura 2 abaixo apresenta uma visão geral do relacionamento entre um container e a forma de gerenciamento.

Figura 2: Métodos de armazenamento – crédito: documentação oficial
Vamos a cada uma delas.
Volumes
A abordagem de volumes permite ao Docker criá-los e gerenciá-los. Eles costumam ser armazenados no diretório /var/lib/docker/volumes. Funciona assim: você cria um volume e dá a ele um nome (ou um label). O nome é um parâmetro opcional. Como acontece com diversos outros recursos dentro do Docker, caso não se informe, será definido um automaticamente usando um conjunto de caracteres aleatórios. Este nome é único em todo o ambiente Docker, isto é, não há risco de conflitar com o nome de nenhum outro recurso pré-existente. O label também é um parâmetro opcional, e pode ser usado como descrição para o volume.
Após criar o volume, o mesmo pode ser apresentado a vários containers diferentes simultaneamente. Como é o próprio Docker quem gerencia o uso de volumes, isso significa que nenhum recurso específico de um sistema operacional é usado, o que deixa a abordagem extremamente portátil. Como assim? O que quero dizer é que, se você roda containers Docker em hosts com sistemas operacionais distintos, como Linux e Windows, o uso de volumes funciona exatamente da mesma maneira nos dois. Nenhuma biblioteca do Linux ou do Windows, ou qualquer outro recurso específico é usado para realizar o gerenciamento.
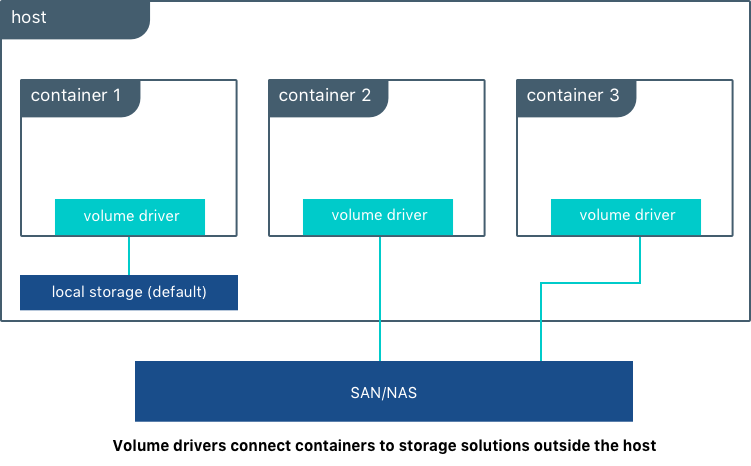
Figura 3: Volumes no Docker – crédito: documentação oficial
Os volumes permitem uma rápida e fácil migração entre hosts Docker diferentes. Caso seja preciso efetuar backup e restore dos mesmos, tais operações são facilmente executadas através de uma simples cópia do diretório /var/lib/docker/volumes. Claro, os containers precisam ser finalizados primeiro. Volumes também podem estar armazenados em hosts remotos dentro do data center, ou localizados em provedores de computação em nuvem. Qualquer sistema de arquivos de rede que possa ser usado pelo host do Docker está disponível. Exemplos seriam o CIFS/SMB, o NFS ou mesmo uma área de storage acessível através de protocolos típicos, como iSCSI ou Fibre Channel.
Pontos de Montagem
Os pontos de montagem (ou bind mounts) correspondem a diretórios (ou arquivos) do próprio host onde o container Docker está em execução. Ele é apresentado ao container através de um mapeamento. Por exemplo, supondo que você esteja usando um host Linux, e tenha disponível um diretório em /home/user/area, você pode montar este diretório no container como sendo, por exemplo, o /var/dados.
Ao gravar ou alterar um arquivo lá, isto será instantaneamente visível ao host. Assim, aplicações que não estejam executando dentro de containers também podem interagir com os mesmos desta forma. Para a mesma situação de backup e restore apresentada no modelo do tópico anterior, aqui é necessário fazer backup do diretório que você escolheu apresentar para o container na forma de um diretório montado.
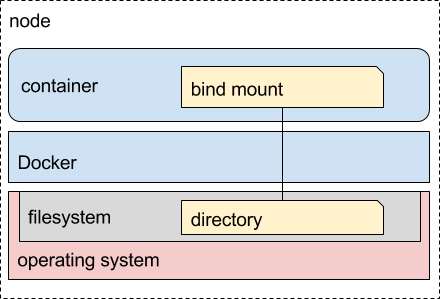
Figura 4: Pontos de montagem no Docker – crédito: Leif Madsen
O diretório no host a ser usado como ponto de montagem no container não precisa existir previamente. Ele é criado no momento em que o container é iniciado. Importante ressaltar que esta forma de armazenamento depende completamente do host onde o container está sendo executado. Assim, caso o container precise migrar entre hosts de sistemas operacionais diferentes, pode haver problemas de incompatibilidade ao usar bind mounts. A documentação oficial recomenda usar volumes sempre que possível.
Atenção: como o sistema de arquivos real do host é apresentado ao container, isto pode implicar em problemas de segurança, com possibilidade de exposição de arquivos e dados sensíveis. Portanto, muito cuidado deve ser tomado ao se optar pelo uso de bind mounts!
tmpfs
Por fim, e não menos importante, como se diz em Inglês, temos o tmpfs. Como você já deve ter deduzido, trata-se de um sistema de arquivos em memória (RAM). Portanto, obviamente que os dados gravados aqui não são persistidos em disco, ficando disponíveis apenas enquanto o container se encontra em execução. Este recurso é usado, por exemplo, pelo Swarm, que é uma forma de cluster em Docker. Vamos ver isto no nosso próximo capítulo. 😉
Informações sensíveis podem ser armazenadas em tmpfs, uma vez que se trata de uma área de memória de uso exclusivo do container que está fazendo uso dele. Se sua aplicação em container necessita de uma área temporária para gravação de arquivos de controle ou mesmo para armazenar senhas ou chaves úteis para algum processo, o tmpfs é a melhor escolha. O uso da memória, em vez de disco, mesmo que SSD, naturalmente confere um desempenho maior ao container.

Figura 5: tmpfs – crédito: itgratis
Ao contrário das modalidades anteriores, não é possível compartilhar um sistema de arquivos tmpfs entre containers diferentes, uma vez que isso infringiria uma regra básica do modelo, que corresponde ao isolamento de memória entre os containers. Um outro detalhe super importante para lembrar: tmpfs está disponível apenas no Docker para Linux.
Cenas dos próximos capítulos
E assim, encerramos nosso capítulo sobre armazenamento. No próximo capítulo, veremos como funciona a comunicação em rede entre containers Docker. Hasta la vista, baby!
Se quiser conferir os outros capítulos:

4 comentários
Diego de Souza · 2018-06-01 às 22:30
Parabéns pelos artigos, muito didático e proporciona uma excelente leitura além do entendimento. Muito bom mesmo, parabéns!!
Maurício Harley · 2018-06-05 às 15:53
Obrigado, Diego!
Isso só me motiva a continuar a série e a ir além com ela, sempre mantendo os artigos o mais acessíveis possível.
Fico feliz que tenha gostado.
vinicius squincaglia · 2018-06-04 às 17:28
parabens otima serie, estou acompanhando e esperando os proximos capitulos 3. Iniciante no mundo docker.. como estou no começo tem alguma dica para testar pois nao tenho nenhuma aplicação para testar o uso do docker persistente ou so subir container e matar container ja aprende
Maurício Harley · 2018-06-05 às 15:55
Olá, Vinícius!
Estou feliz por ter gostado. Obrigado pelos elogios. No próximo capítulo, ou no seguinte, já vou colocar exemplos práticos sim, envolvendo todos os componentes e conceitos abordados. Aguarde e confie. 😉
Por hora, leia o livro do Rafael Gomes, vulgo @gomex, “Docker para Desenvolvedores”: https://leanpub.com/dockerparadesenvolvedores